Designing Linear Horizontal Throughput with Real Atlas Capacity Numbers
Scaling MongoDB to 100K Writes per Second is not a tuning exercise — it is an architectural decision.
It is architecture.
To make this concrete, let’s assume a realistic MongoDB Atlas shard with:
- 32 GB RAM
- 8 vCPU
- Standard SSD storage (no provisioned IOPS)
- Sustainable throughput: ~18,000 inserts/sec
These are not extreme specs.
They are attainable production configurations.
Now the question becomes:
Why Scaling MongoDB to 100K Writes per Second Requires Horizontal Sharding ?
Scaling MongoDB to 100K writes per second cannot be achieved with vertical upgrades alone because a single node—even with generous RAM, CPU, and I/O—quickly reaches physical limits. Real sustained throughput at this level requires distributing write operations across multiple independent write engines. Horizontal sharding turns each shard into its own writer with dedicated CPU, memory, disk bandwidth, and replication capacity, allowing the cluster to ingest writes in parallel rather than funneling every operation through a single bottleneck. By spreading load evenly across shards with a well-designed shard key, adding more shards directly increases overall throughput in a near-linear fashion, which is the fundamental architectural principle that enables six-figure write rates without overwhelming any single resource.

What 100K Writes per Second Really Means
100K writes/sec equals:
- 6 million writes per minute
- 360 million writes per hour
- 8.64 billion writes per day
At this scale:
- Vertical scaling plateaus.
- I/O becomes visible.
- Replication pressure increases.
- Hotspots destroy symmetry.
The only stable strategy is horizontal scaling.
Baseline: One Shard = ~18K Inserts/Sec
With our assumed Atlas shard (32 GB RAM, 8 CPU, standard disk), we can sustain:
≈ 18K inserts/sec under controlled conditions:
- Moderate document size
- Minimal secondary indexes
- Bulk writes
- No heavy aggregation inline
- WriteConcern aligned to SLA
This becomes our building block.
Each shard is an independent write engine capable of ~18K/sec.
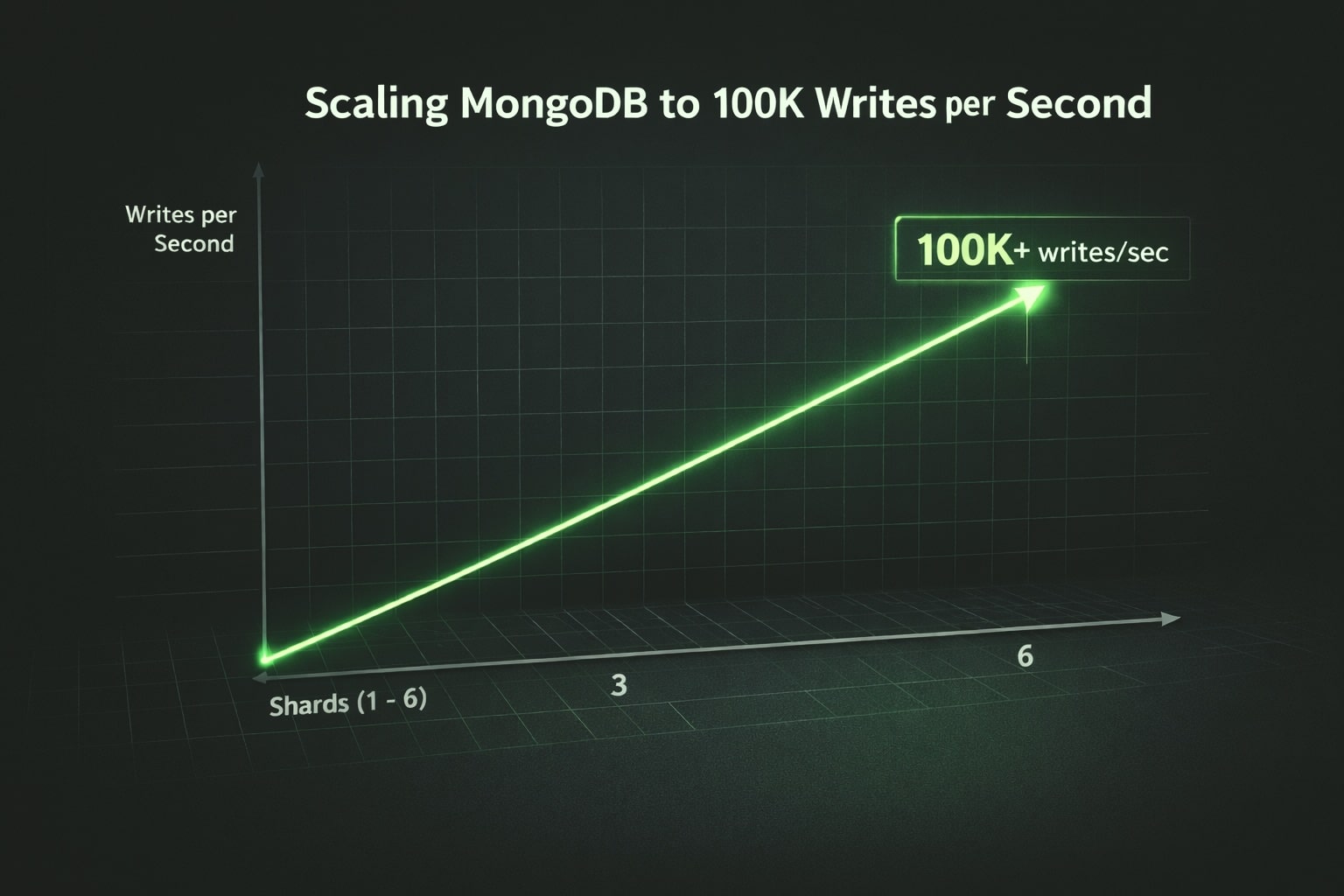
The Math of Linear Horizontal Scaling
If one shard handles ~18K/sec:
- 4 shards → ~72K/sec
- 5 shards → ~90K/sec
- 6 shards → ~108K/sec
That means:
Six shards of this tier cross the 100K writes/sec threshold.
No exotic hardware required.
No pre-allocated IOPS.
No vertical scaling.
Just symmetry and distribution.
That is horizontal scaling in practice.
Why This Works
Each shard:
- Has its own storage engine.
- Writes to its own disk.
- Replicates independently.
- Uses its own CPU and memory.
When writes are evenly distributed, throughput becomes additive.
Total cluster throughput ≈ Sum of shard throughput.
The architecture scales because there is no shared write bottleneck.
Real-World Throughput Observation on a 5-Shard Cluster
The following Atlas metrics snapshot shows sustained ingestion reaching ~80K inserts per second across five shards. With an average of ~16K writes/sec per shard, the observed throughput aligns with the expected per-shard capacity discussed earlier.

The slight delta between the theoretical ~90K ceiling (5 × ~18K) and the observed ~80K reflects real-world operational overhead including replication, network variability, and writeConcern constraints.
This validates the linear horizontal scaling model: throughput grows proportionally to shard count as long as distribution symmetry is preserved.
Step 1: Shard Key Engineering
At 100K/sec, shard key quality becomes existential.
Example:
sh.shardCollection("db.collection", { partitionKey: 1 })Requirements:
- High cardinality.
- Uniform distribution.
- No monotonic growth.
- Deterministic routing.
At 18K/sec per shard, even a 10% imbalance creates:
- 19.8K/sec on one shard
- 16.2K/sec on another
That overloaded shard becomes the cluster ceiling.
Distribution must be symmetric.
At this scale, shard key design cannot be separated from data modeling decisions. Document structure, cardinality, and write patterns directly influence distribution symmetry and write amplification, as explored in our deep dive on data modeling for scalable MongoDB architectures
Step 2: Pre-Split and Control Chunk Placement
With standard disks (no provisioned IOPS), you cannot afford chunk migrations during peak ingestion.
Pre-split before load:
sh.splitAt("db.collection", { partitionKey: 250000 })
sh.splitAt("db.collection", { partitionKey: 500000 })
sh.splitAt("db.collection", { partitionKey: 750000 })Then move chunks explicitly.
Why?
Because chunk migrations consume:
- Disk bandwidth
- Replication bandwidth
- CPU
- Network
At 18K/sec per shard, you want ingestion capacity dedicated entirely to writes.
Predictability equals stability.
Step 3: Optimize the Write Path
At this scale, inefficiencies multiply instantly.
Best practices:
- Bulk writes (insertMany)
- ordered: false
- Lean documents
- Minimal secondary indexes
- Avoid multi-document transactions
Example:
writeConcern: { w: "majority", j: false }depending on durability requirements.
Important:
Every secondary index adds write amplification.
If a shard sustains 18K/sec with 2 indexes,
adding 5 more indexes might reduce that to 10K/sec.
Index discipline defines throughput ceiling.
Storage Reality: No Pre-Allocated IOPS
Standard Atlas storage without provisioned IOPS means:
- Burst I/O capacity exists.
- Sustained I/O must stay below disk limits.
- Write spikes can cause latency variation.
At 18K/sec per shard:
- Disk latency must remain stable.
- Journaling strategy matters.
- Replication lag must be monitored.
This is why horizontal scaling is safer than vertical scaling.
Vertical scaling increases pressure on a single disk subsystem.
Horizontal scaling distributes I/O across multiple disks.
Step 4: Separate Ingestion from Everything Else
At 100K/sec, never mix ingestion with:
- Heavy aggregations
- Complex validations
- Cross-document checks
- Analytical queries
Instead:
- Perform ingestion only.
- Emit completion events.
- Use Change Streams.
- Process analytics asynchronously.
The write path must remain isolated. Isolation protects throughput.
What Breaks 100K Writes per Second
With our 18K/sec shard baseline, common failure modes are:
- Monotonic shard keys.
- Too many secondary indexes.
- Large document size.
- Chunk migrations during peak.
- Journaling under disk saturation.
- Insufficient connection pooling.
- Application-side bottlenecks.
At 100K/sec, small inefficiencies scale catastrophically.
Infrastructure Symmetry Is the Secret
To sustain 100K+ writes/sec with six shards:
- Each shard must have identical hardware.
- CPU usage should remain below saturation.
- Disk utilization must remain below I/O ceiling.
- Replication lag must stay stable.
- Balancer should not compete with ingestion.
Cluster average metrics are misleading. Per-shard metrics tell the truth.
Final Takeaway
With a realistic Atlas shard:
- 32 GB RAM
- 8 CPU
- Standard SSD
- ~18K inserts/sec sustainable
You need:
≈ 6 shards to exceed 100K writes/sec.
No exotic tuning. No vertical extremes.
Just:
- Correct shard key.
- Deterministic distribution.
- Clean write path.
- Index discipline.
- Horizontal symmetry.
At that point, 100K+ writes per second is not a miracle.
It is arithmetic And when performance becomes arithmetic, your architecture is correct.





