The technological revolution continues to surprise us day after day! Today, one can give “eyes and a brain” to a computer. This concept is known today as Cognitive Computing. Indeed, computers might not possess cognitive abilities, but they are capable of executing operations which completely rely on human perceptions. It’s always possible to use the power of automation: from handwriting recognition, face identification and behavioral pattern determination to any task requiring cognitive skills, computers are capable of delivering the right solutions. At the end of 2016 year Microsoft announced the availability of a set of services called Microsoft Cognitive Services. Cognitive Services provides simple APIs that handle common use cases, such as recognizing speech or performing facial recognition on an image. These APIs can be broken down into five main categories: vision, speech, language, knowledge, and search. They are all based on machine learning algorithms.
In this blog post, I’m going to explore the Computer Vision, which returns rich information about visual content found in an image. Computer vision is multidisciplinary, routinely serving visual processing and analytic components to ambitious projects such as the development of personal robots, self-driving cars and autonomous drones. Artificial intelligence and machine learning are widely embraced in efforts to automate computer vision tasks such as 3D recovery, facial and object recognition, image and video captioning, biometric security, medical imaging and video enhancement.
The Computer Vision has many features that include the ability to analyze a picture to understand its content, create smart thumbnails as well as OCR and adult content detection.
Many scenarios within our customers today require humans to perform visual checks, the ability to automate these tasks increasing accuracy, scalability and improve the efficiency for our customers, moreover few scenarios can be enable due to minor cost. Beyond detection of every day objects that the Computer Vision can already perform, it’s a fundamental requirement to have training data enabling a custom model to identify additional objects (e.g. cars, machines, defects) therefore a customer must be able to provide this data to training the service. So training the service is possible to have implement:
- Image Classification (detecting presence of objects)
- Object Detection (detecting location/count of objects)
During last year I used the computer vision to many scenarios, from fun purpose as to check the number of toys left on the floor of kids bedroom to Customer production’s scenarios.
Here are some example where the computer vision can be a game changer:
Safety on construction site:

object and facial recognition could be used to keep an eye out for health and safety violations in your workplace, running more than 27 million recognitions every second. The Computer Vision object recognition capabilities allows to instantly respond with a message indicating that a jackhammer was available on the site. Moreover it is also possible to monitor which employees are certified to use the piece of equipment, and who handled it most recently, by scanning faces as different people pick up the item. In the eventuality that an employee without the proper authorization picks up a particular piece of equipment, a violation notification will be distributed to the appropriate personnel, moreover the system can even make sure that items on the site are being stored safely, by referring to tagged locations that are set up for individual tools.
Quality control:

object recognition to check the quality of a industrial component, the automatic inspection of mechanical parts containing defects can improve and to speed the check of high quality piece in production line:
Situational awareness

a camera will effectively become a robot with situational awareness, capable of tracking and classifying every object and person in its vicinity, from a old-man with a reduced mobility or waving hand or smiling face to stress on a beam or an improperly parked vehicle. Moreover this solution will be able to identify situations such as a person leaving luggage unattended, a car being driven into an airport concourse and abandoned, or people congregating in an unusual way.
Other example is this intelligent surveillance system to the traffic control, it can greatly increase the public security of our society, computer vision is able to describes properties of vehicle visual tags, including vehicle color and vehicle type.
Dangerous situations

the computer vision can improve the public safety by using live CCTV near train crossroad to analyze real situations and for example to spot people who are near the cross road.
Medical Imaging
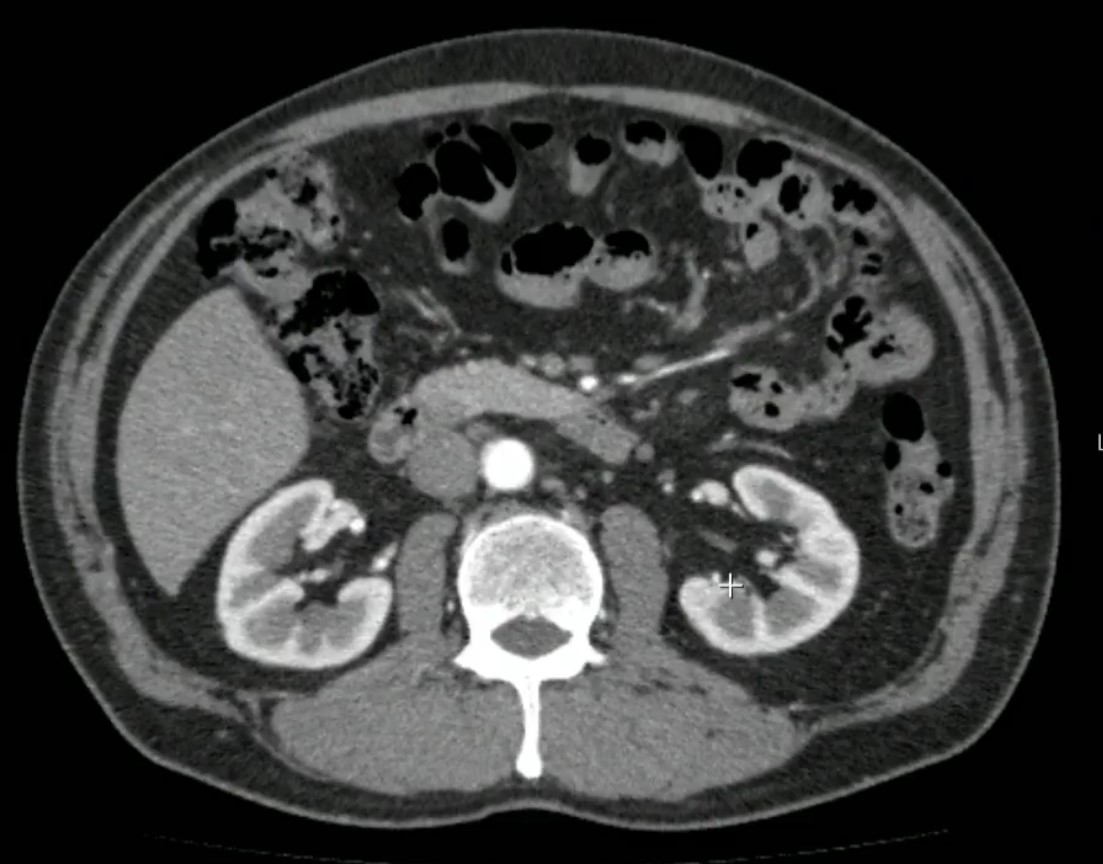
the computer vision is the fuel of InnerEye project used for the automatic delineation of tumors as well as healthy anatomy in 3D radiological images. Project InnerEye builds upon many years of research in computer vision and machine learning, it employs algorithms such as deep decision forests (as used already in Kinect and Hololens) as well as convolutional Neural Networks for the automatic, voxel-wise analysis of medical images. The technology is designed to be of assistance to expert medical practitioners.
Seeing AI

By combining computer vision with the other Microsoft Cognitive Services a person who is visually impaired can better understand who and what is going on around them. A specific application will analyze and translate the image to speech and describe what the person is doing, how old they are, and what emotion they’re expressing. A user can take an image of text from a nutrition label to a news article and the app will read it to the user.
In other scenarios with very complex visual models or where the performance are stressed or perhaps higher volumes of data are required then an export to CNTK (leveraging the upcoming Computer Vision Toolkit CVTK) will be provided enabling data scientists greater control and flexibility whilst still benefiting from some Custom Vision capabilities. An offline edge option for Custom Vision will also exist for scenarios that don’t lend themselves to Azure web-service integration.